Hello,
Seth here, I am a senior engineer at Kagi. I am going to provide a post-mortem of the major outage across all regions which started on June 4th 2025. I will also describe our next steps on what we will do to mitigate these problems in the future.
Also responding with me on this was Luan, our DevOps engineer, and Daniel, our Site Reliability Engineer (SRE).
Timeline
17:09 4/6/2025 - Alerts were triggered indicating that kagi.com was unavailabe
17:15 4/6/2025 - Confirmation that a DDOS was underway
17:17 4/6/2025 - status.kagi.com updated with incident
17:35 4/6/2025 - kagi.com is online again
19:23 4/6/2025 - DDOS pauses and resumes multiple times with different targets
08:00 5/6/2025 - DDOS is focused mainly on kagifeedback.org and orionfeedback.org
15:00 6/6/2025 - DDOS stops
Key points
We recorded a peak of 7 Gib/s of network traffic being sent to/recieved from kagifeedback.org *after* IP blocking rules were applied
Requests blocked / second
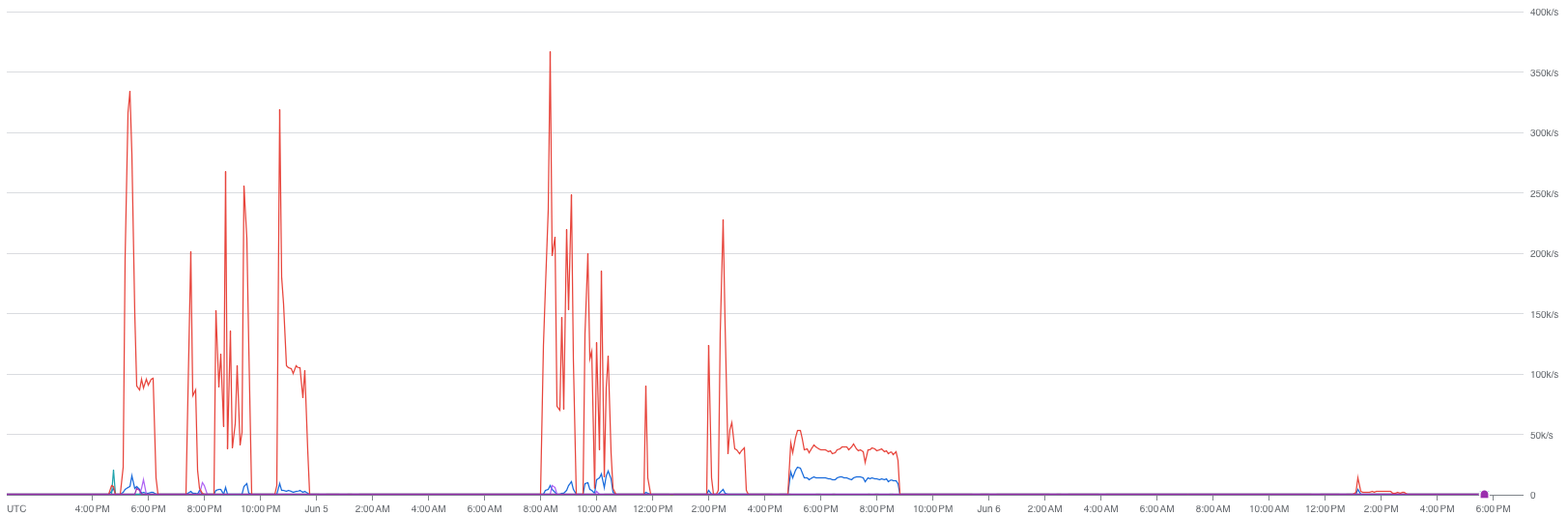
note: because of the time range, peaks appear lower.
Details
Discovery
At around 17:09 UTC on June 4th 2025, we started getting alerts from our internal monitoring that all regions were suddenly receiving 504/503 status codes and reporting 'no healthy upstream'.
At the same time, we also started getting pings from our users about users not being able to access Kagi at all in our Community Discord.
We immediately jumped into action and hopped on a call to investigate the cause.
We started by looking into system and database resources, as we noticed some database connection issues from our internal monitoring and we started to look at our internal metrics we collect from our servers for some further insight into what was going on.
There was a spike in CPU usage on the VMs (but only up to about 20%), but otherwise everything seemed normal, which was strange!
We then started to investigate incoming requests and noticed that we were being hit with a large volume of requests, all coming from different IP addresses in data centers and residential connections around the world.
We were being targeted with 400 thousand requests per second (compared to our normal load of around 400 req/s)!
After looking at further internal metrics that we collect, we noticed a huge spike in queued fibers that were ready to be resumed from the language we use (Crystal).
To put fibers simply, they are essentially little workers that all take turns running, pausing when they need to wait for something so that things can run concurrently.
During all of this, it was reaching peaks of around 7,000 fibers queued and waiting to resume! (We normally only see around 70-100 at a time in typical usage, so this was A LOT more.)
This was causing our web application to slow to a halt, because things were being queued at a very fast rate, but processing them was taking more time than it took to add them.
Now that we knew it was a clear DDoS attack, we began to take action.
Action
We already had some general rate-limiting rules already in place for such events, which were blocking some requests, but others were slipping through and hitting our servers.
The incoming requests were unauthenticated, so we began fine-tuning our rate limits to be stricter for these attacks.
At around 17:35 UTC, all services had come back online, and users reported they could access Kagi again!
The DDoS attack continued until around 18:15 UTC, sustaining around 100,000 req/s, with all requests being blocked by our rate-limits during that time.
We thought this was the end, but at around 19:30 UTC, they returned and hit us again with the same 400k/req/s, which resulted in some brief downtime again before our rate-limiting rules caught up and blocked them.
Things tapered off at around 20:00, but returned again at 20:30 UTC, this time sending over 600,000 req/s before slowing back down to 100,000 req/s, with various spikes back up to 400k/req/s and so on.
During all of this, we applied multiple mitigation strategies, such as scaling up our VM count to distribute the load more evenly, and implementing additional rate-limit rules targeting certain common patterns in the malicious traffic to prevent them from reaching our backend.
As rate limit rules were still allowing an initial surge of traffic though, we changed strategies and starting blocking the IP addresses involved in the DDOS.
We observed no further downtime on kagi.com after applying these mitigations, even while the attacker continued to send high volumes of requests.
The DDoS attack went on and off throughout the night and next day, mainly hitting our feedback forums the next day.
The type of traffic hitting our feedback forums was slightly different. Instead of hitting us with a load of 600K req/sec, which we easilly identified and blocked, they included a different set of servers that would only make 1-10 req/minute, but overall still contributed to a large amount of requests that snuck through our blocking rules.
We made some configuration changes in the service in order to catch these attacks that sneak under our limits, and the feedback forums recovered.
Next Steps
We will:
continue to monitor the situation and fine-tune our rate-limiting policies to ensure they effectively prevent bad actors
set up additional autoscaling rules to more efficiently scale
evaluate our backend servers and services for additional changes to mitigate similar issues in the future
We would like to thank all of our community users for immediately notifying us about the issue in our Community Discord (https://kagi.com/discord) and for being extremely supportive throughout the entire duration of the downtime.
Thank You!

